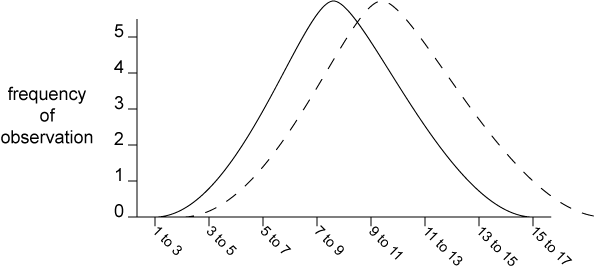
Each sample represents a population of all of the trees the investigator could possibly plant, grow, and measure. Each data set gives us a sample mean that estimates the true mean of the population. We want to estimate the probability that the true means are different for the two populations that these data represent.
The investigator measured only 12 trees in each sample, giving her rather small sample sets. Generally any data set of n < 30 is considered to be small. We have to modify the theoretical distribution to work with small sets because random error affects small samples more so than larger ones (recall the plots of 2 and 6 data points that you made previously). We won't go into the theory here. The t distribution was worked out more than a century ago by W.H. Gossett, who is responsible for the name "Student" that is applied to the two sample test that is based on it. Instead, we will go straight into the test itself.
Why not call it Gossett's distribution? Gossett was under contract and prohibited from publishing under his own name. He had to publish his work using a pseudonym, namely "Student." This is why we put "Student" in quotation marks when we refer to "Student's" t test.