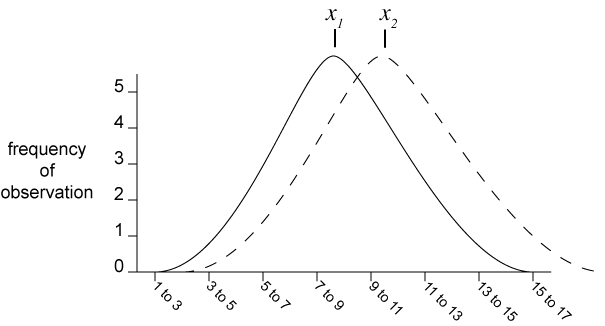
Each sample represents a population of all of the trees the investigator could possibly plant, grow, and measure. Each data set gives us a sample mean that estimates the true mean of the population. We want to estimate the probability that the true means are different for the two populations that these data represent.
Two pieces of information enter in to the determination. One is the difference between the two sample means. The bigger the difference, the more confident we are that the true means are different. The second is the extent of error in the two data sets combined. The greater the error, that is, the more the data are scattered, the less confident we are that the true means are different.
Unfortunately, we have to throw in just a bit more terminology at this point. You should recall that a hypothesis is a testable statement. What we call a null hypothesis is the prediction that there will be no effect, no change, or no difference. What we call an alternative hypothesis is the prediction that something will happen. There can be just one null hypothesis, but there can be more than one alternative hypothesis.
What is the null hypothesis for this study?
What is/are the alternative hypothesis(es)?