Instructions for SPSS
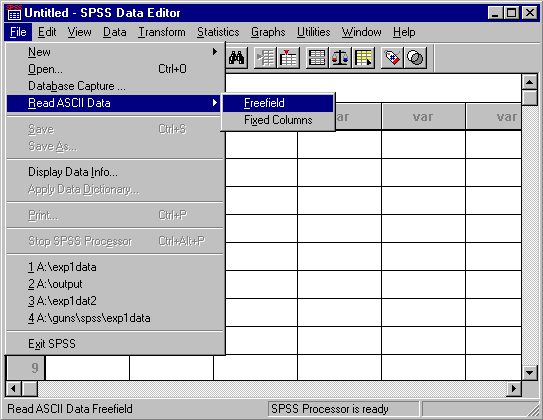
To input the data into SPSS we need to change the data file. SPSS cannot read the variable names from the data file so we must delete the first line of the data file before we import it. BE SURE TO REMEMBER WHICH COLUMNS ARE WHICH because we will need to give SPSS the names later. In order to import a simple text file into SPSS we need to use the "Read ASCII Data" option found under the "File" menu. So, let's get started. First select the Read ASCII Data" option under the "File" menu. You will be given two choices. Choose "Freefield":
Then a window should pop up asking for the variable names and type (numeric or string) of each one. The variable names must be entered in the order which they appear. So the first variable name is "subno" and is of type "Numeric" . Then click the "Add" button and the name should be added to the "Defined Variables" box on the right. Continue in this manner until "sex", "aw", "an", "cxew" and "cxen" are all entered. The following picture shows what it should look like right before the last variable "cxen" is entered:
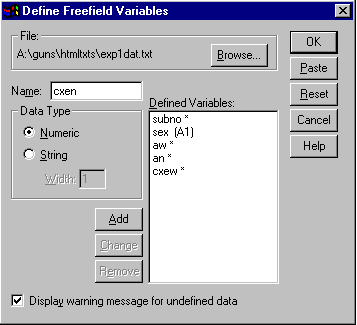
Notice that "sex (A1)" appears in the "Defined Variables:" box. This is to denote that "sex" is of type "String" and has "Width" of 1. If your list does not look like this, click on the "sex" variable in the "Defined Variables" box and make the appropriate changes. Click the "Change" button when you are done. After all the variables are entered in the "Defined Variables" box, click the "Browse" button and find the appropriate location of your file (you will have needed to copy the data to a text file and saved it on your local machine - also you want to make sure that "all files (*.*)" shows in the "Files of type:" bar). When this is finished, click "OK". The data editor will look like this:
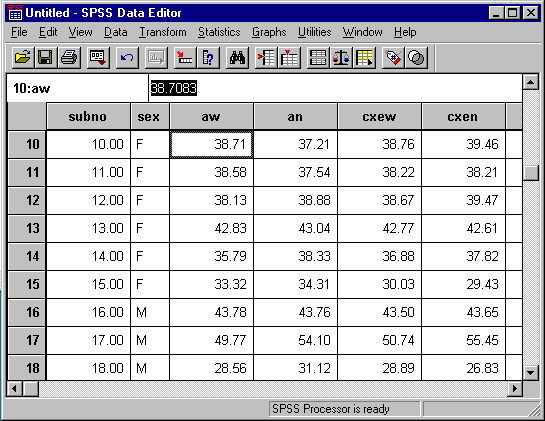
It should now show the data set with the proper column titles. You might notice that the numeric fields only have the numbers reported to 2 decimal places. If you click on a cell, however, you will see that the full number has been retained and only the first 2 decimal places are seen. If this bothers you, you can change it by first selecting a variable in the editor and then choose "Define Variable..." under the "Data" menu. Then click the "Type" button on the window and change the "Decimal Places" to however many you need.
how to input data
All the descriptive statistics - the summary statistics, the box plots, and the normal
probability plots can be done with the "Explore" option:
go to the "Statistics" option on the menu bar and select "Summarize" and then "Explore":
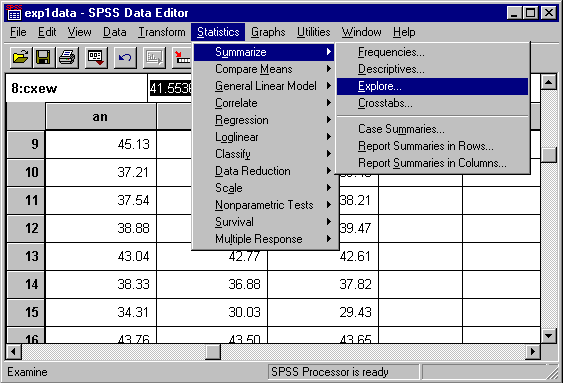
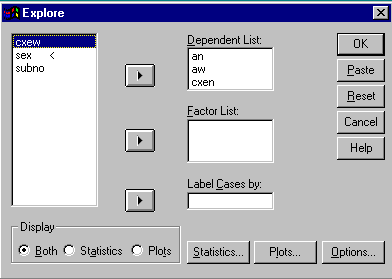
When the next window pops up, Highlight the variable "an" and
click the ![]() button beside the "Dependent list:"
sub-window. Repeat this procedure for the variables "aw", "cxen",
and "cxew" so that they all appear in the "Dependent list:"
sub-window. (see below)
button beside the "Dependent list:"
sub-window. Repeat this procedure for the variables "aw", "cxen",
and "cxew" so that they all appear in the "Dependent list:"
sub-window. (see below)
Next click on the ![]() button and choose the following
options:
button and choose the following
options:

Notice that the "Normality plots with tests" option is checked. This will produce the Normal Probability plots seen in the output and a test of normalcy will accompany the plots.
Also notice that for box plots the option "Dependents together" is chosen. This produces the side by side boxplot instead of a separate boxplot for each variable.
Click "Continue" and then click "OK" on the "Explore" window.
As an aside, SPSS has several ways to do the same thing. If you only want part of the "Explore" output, you can taylor the output as we have above, or you can choose different options entirely. For example, if we wanted just the box plots, we could choose the "Graphs" option and then choose "boxplots" and we would get the same boxplots we did in "Explore". Also, if you want just the summary statistics, then you can choose "Summarize" and then "Descriptives" and then choose which statistics you want reported.
Comparing the different conditions
There are several different ways to compare the different conditions. First we used Anova and then we used a t-test.
To perform an Analysis of Variance in SPSS we use the "General Linear Model" option found under the "Statistics" menu:
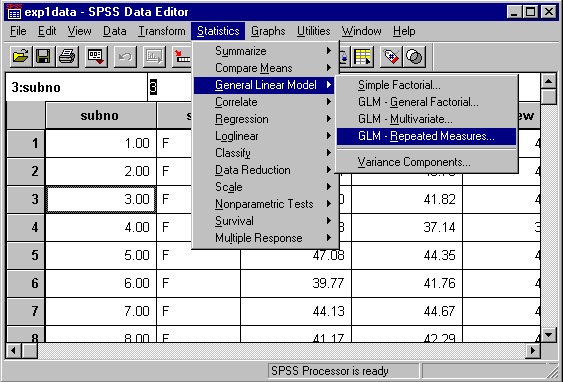
Be sure to choose the "GLM - Repeated Measures..." option since we are dealing with a within subjects design. When the "Define Factors" window pops up, go to the box "Within-Subject Factor Name:" and type the first main effect: "prime". The number of levels for this factor is 2. Then click the "Add" button. the Factor "prime(2)" should appear in the lower box. (see below)
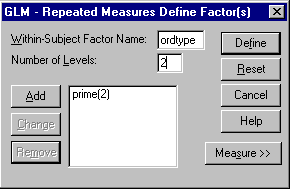
Next we want to create our next factor "wordtype" with 2 levels.
Repeat the above procedure and again clicking "Add" should add it
to lower box. With both factors in the lower box, we are ready to define each level.
Click the "Define" button and the next window should pop up. Notice
how the box under "Within-Subjects Variables (prime,wordtype):"
has several blanks : "__?__(1,1)" The numbers in the parenthesis
refer to the level of the factor in that position. For this example, this blank we
want to fill with the variable name which corresponds to the first level of prime
(Weapon) and the first level of wordtype (aggressive). So the variable corresponding
to these conditions is "aw". So we highlight "aw"
and then click the ![]() button. "aw" will fill
the first blank. Repeat this with the rest of the variable in the appropriate order
(see below if you aren't sure what that is:)
button. "aw" will fill
the first blank. Repeat this with the rest of the variable in the appropriate order
(see below if you aren't sure what that is:)
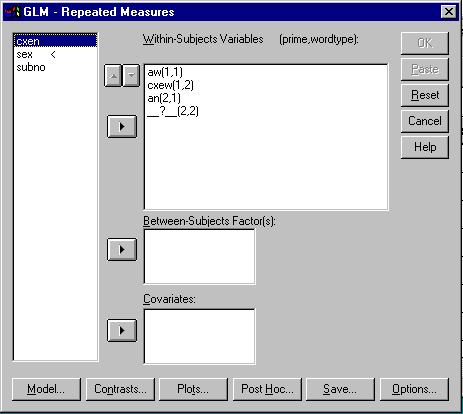
Since there are no between-subjects factors and
no covariates we leave those blank. Now click on the ![]() button
so we can get the plot of the main effects:
button
so we can get the plot of the main effects:
Select "prime" for the "Horizontal Axis" and
"wordtype" for the "Separate Lines" by hilighting
the variable and clicking the appropriate ![]() button.
button.
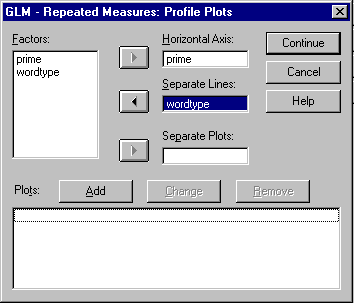
Once both are filled, click the "Add" button and "prime*wordtype" should appear in the lower box. Since we have no other plots, click the "Continue" button. Then go back to the previous window - "GLM - Repeated Measures" and click "OK".
The dependent variable needed for this analysis is the difference between two
priming scores:
1. Aggresive word neutral prime - Aggressive word weapon prime
2. Non-aggresive word neutral prime - Non-aggressive word weapon prime
To compute this dependent variable, do the following:
Choose "Compute" from the "Transform" menu.

In the formula window, place the name of the new variable in the "Target
Variable" box. We want to make a new variable "diff" and it
will be the formula (an - aw) - (cxen - cxew). To get the variable names into
the formula, use the usual method of highlighting the names of the variables and
using the ![]() button. For the minus sign and parenthesis,
simply click on keypad.
button. For the minus sign and parenthesis,
simply click on keypad.
Now click the "OK" button and the column "diff"
should be added to the data.
Now, with the new variable, "diff" you are ready to perform the
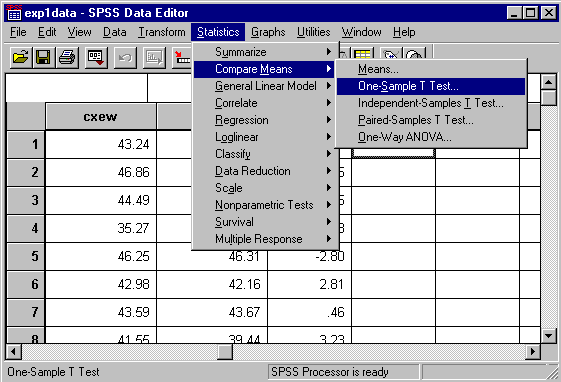
t-test. Go to the "Statistics" menu and choose the "Compare
Means" option. Then choose the "One-Sample T Test" option:
Choose "diff" as the "Test Variable(s)" by highlighting
"diff" from the left box and clicking the ![]() button.
button.
Your window should now look like this:

Click "OK" and SPSS will perform the t-test.
SIDE NOTE - If we arrange the data differently, this could also be done with the "Paired-Samples T Test" option. Instead of the one new difference score, we make two new variables, one for the weapon prime condition aggression accessibility score "(cxew-aw)" and one for the nonweapon prime condition aggression accessibility score"(cxen-an)", in the same way we created the variable "diff". Then we select the "Paired-Samples T Test" option and select the two new variables.
Between-Within Subjects ANOVA:
If we want to see if gender has any effect on the results, we need a between subjects design since gender is a between subjects effect. In SPSS this is easy to do. Everything mimics the procedure we used before for the Within-Subjects ANOVA: we need to declare our two factors "prime" and "wordtype". Choose the "General Linear Model" option found under the "Statistics" menu. Then choose the "GLM - Repeated Measures..." option. When the "Define Factors" window pops up, go to the box "Within-Subject Factor Name:" and type the first main effect: "prime". This factor has 2 levels. Then click the "Add" button. Do this same procedure for the second factor "wordtype" which also has 2 levels. Then click the "Define" button and the next window should pop up.
Again we see that "Within-Subjects Variables (prime,wordtype):"
has several blanks : "__?__(1,1)" The numbers in the parenthesis
refer to the level of the factor in that position. For this example, this blank we
want to fill with the variable name which corresponds to the first level of prime
(Weapon) and the first level of wordtype (aggressive). So the variable corresponding
to these conditions is "aw". So we highlight "aw"
and then click the ![]() button. "aw" will fill
the first blank. Repeat this with the rest of the variable in the appropriate order
(see below if you aren't sure what that is:)
button. "aw" will fill
the first blank. Repeat this with the rest of the variable in the appropriate order
(see below if you aren't sure what that is:)
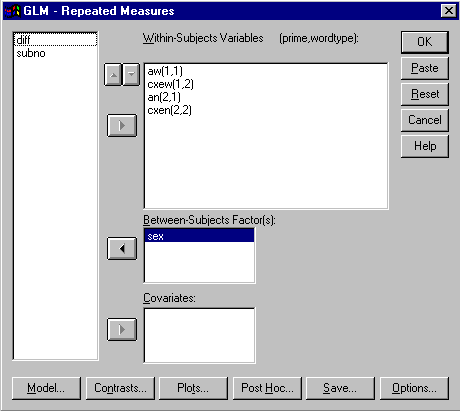
The only difference is that now we want to select the
variable "sex" for the "Between-subjects Factor(s)"
Do this by hilighting "sex" in the left box and hit the ![]() button beside the "Between-Subjects Factor(s):" box so that "sex"
appears in that box (see below):
button beside the "Between-Subjects Factor(s):" box so that "sex"
appears in that box (see below):
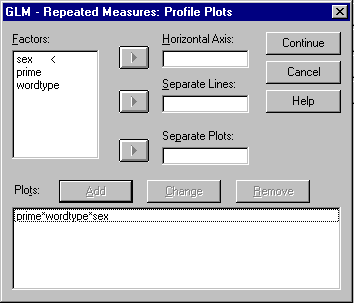
Now, again we want to make a profile Plot of the main effects and the interactions.
Click the ![]() button and when the "GLM - Repeated
Measures: Profile Plots" window pops up, choose "prime"
for the "Horizontal Axis" by highlighting "prime"
and clicking the
button and when the "GLM - Repeated
Measures: Profile Plots" window pops up, choose "prime"
for the "Horizontal Axis" by highlighting "prime"
and clicking the ![]() button beside the "Horizontal Axis"
box. Assign "wordtype" to the "Separate Lines"
box the same way, and then, assign "sex:" to the "Separate
Plots" box. the same way. With all 3 boxes filled, click the "Add"
button and then "prime*wordtype*sex" should appear in the lower
box (see below):
button beside the "Horizontal Axis"
box. Assign "wordtype" to the "Separate Lines"
box the same way, and then, assign "sex:" to the "Separate
Plots" box. the same way. With all 3 boxes filled, click the "Add"
button and then "prime*wordtype*sex" should appear in the lower
box (see below):
Finally we click "Continue" which brings us back to the previous window. Then we click the "OK" button and SPSS performs the between Within ANOVA.